
I’m not going to tell you to unit test. If you don’t know what unit testing is or why’d you do it, well there are plenty of books out there.
The idea is simple. You write some tests for some specific inputs and check if the output is what you’d expect. You can also put in some special cases, usually after the code broke.
A unit testing example and its problem
Let’s take a seemingly trivial example. I want to test the toLowerCase function. What would you test?
Most of the time people would test a single input point like this:
assertEquals(“a”, toLowerCase(“A”));
and perhaps someone got creative and tried this:
assertEquals(“a”, toLowerCase(“a”));
The problem is that you stab at the problem one input at a time. If there is a sea of possible input what should you check? Write a test for each input/output pair?
I’d like to present a different way of testing that I believe is more effective in finding bugs.
Distribution testing
Instead of testing one point we test a whole range of input values. In our example we’ll test each possible character. If you’re like me you’ll probably be having the following character class in mind: [a-zA-Z]. But it’s so much broader than this.
As input let us take a flat distribution of each element over the range of [0..65535]. But let’s keep it simple for now [0..255]. As a histogram this renders as a boring flat line of 1 element at each point. I’ve not put in a screenshot as I assume you’ve seen a flat line before. The output however is slightly more exciting.
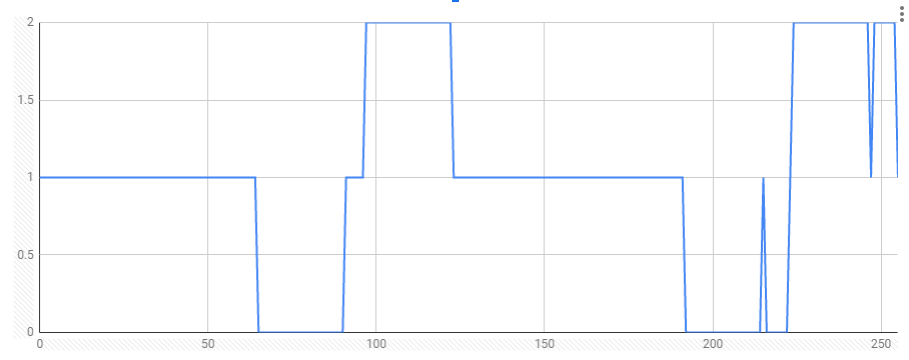
The X axis is the character ordinal value. The Y axis is the amount of times we’ve seen this character.
We find that there are 3 cases in this histogram. The case in which the character isn’t converted. This gives us a value of 1. There are evidently also the characters that are converted into another character like A => a. That’s what’s happening in the first depression. It is countered by a small lift of all characters from [a-z].
At 200 we can see a small range of accented characters like “À” which converts into à. But there is one spike out there that is interesting. What’s going on at 215? Maybe it’s something worth examining? The character we find there is × and the depression that follows is ÷. Funny how they are each others opposite. It makes sense.
But what else can this technique deliver except for finding some weird outliers? We can also check that the sum of all characters should be 256 (which it does).
Another self-evident case: sql injection
Had everyone used this technique or used any modern database access technique there never were something as a SQL injection. Why not?
If they were testing all characters you’d quickly see their program crashing on ‘ and backslash characters. This should give you a quick hint that you’re doing something wrong. Sadly most people only test with evident examples. Hopefully this technique can help find such problems in the future.
Conclusion
I believe that looking into the output distribution of your code can show you surprising things and surface bugs you’ve never thought of. Sure it takes some time from your end as a programmer and becomes more complex as you have multiple inputs. Visualizing also helps you think deeply about your code and the cornercases or how distributions come together.
Is this merely intellectual exercise or is it truly a useful tool? Let me know.

Chek out Haskell’s Quicktest and the like.
LikeLike