
Tags
What’s this about?
Everyone knows google. Some even know other search engines.
Way back it used PageRank as a means as identifying the more popular pages. It would then use the popularity(how many people link to that page) of that page. This tactic makes me sad. It encourages people to read the same popular junk over and over again. A simple example is Batman. No not the superhero, the location in Turkey(https://en.wikipedia.org/wiki/Batman,_Turkey).or how about a servant to an army officer?
It looks as if facts and non fiction is becoming secondary to popular culture, which is pretty wrong and something for another discussion.
But is it useful because it is popular? SEO link farms and other SEO optimizations may be the living proof it is broken.
To get a better idea of the workings I wrote my own crawler . Not because I think I can compete with Google but as a thought experiment on what can be done differently.
Architecture
By making the system flexible I cowardly avoid taking any design decisions whatsoever. Here are the components I came up with.
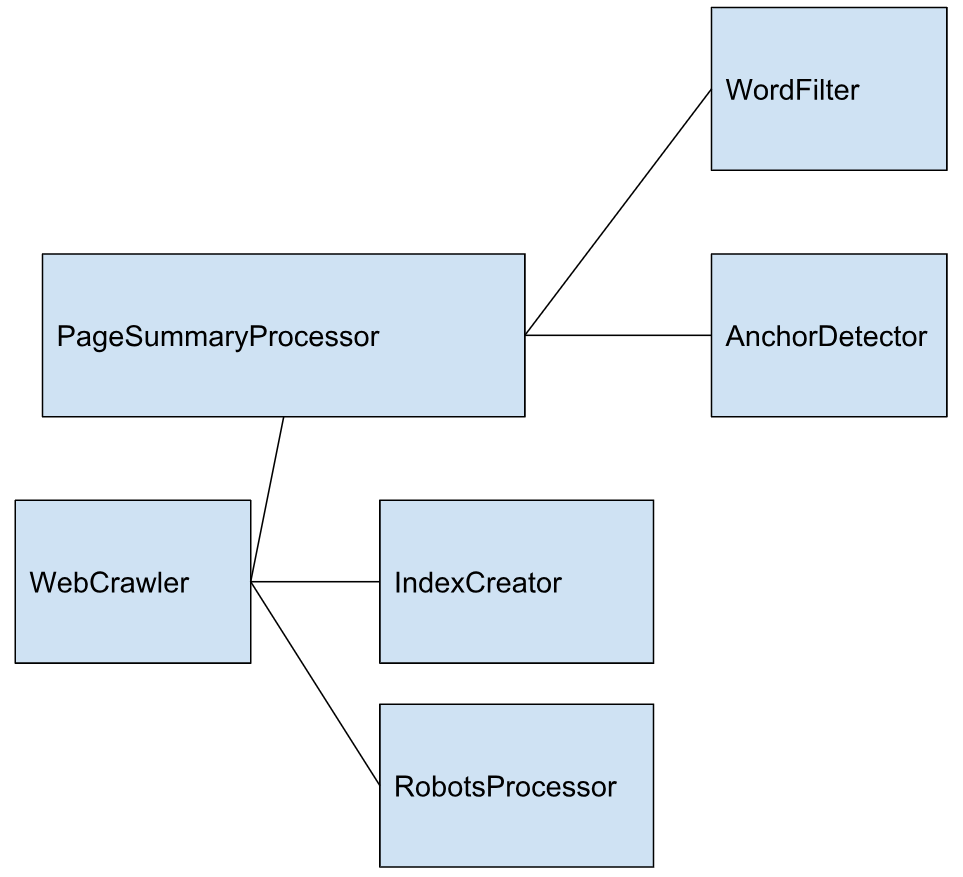
This simple system of interfaces allows for a very simple webcrawler. The webcrawler decides the strategy on how to go through the URLs. It gets a summary (content and other links) by using a PageSummaryProcessor.
PageSummaryProcessor
JSoup was used to download the contents of the pages.
Not all words are equally interesting. So I decided to skip the most common words like ‘the’, ‘and’ etc. These are filtered out by a WordFilter.
Webcrawler
This summary comes back to the webcrawler. The Webcrawler will then store this information in an index. The IndexCreator stores the content.
Not all pages should be crawled however. A robots.txt file makes sure some pages, such as a login page or a “print this page” button, are not indexed. I found out that some crawlers disrespect proper crawl-delays and are denied access as broadly as possible. Bad crawlers do bad things with the bandwidth. Crawlers however are a necessary evil. Without them no one will find your content.
Webcrawling strategies
Simple crawling
The simplest strategy is to just have one thread and crawl without any limits. Some hosts like reddit.com quickly stop overly aggressive crawlers by rate-limiting.
Respectful crawling
It’s better to crawl with respect to the crawl delay. A crawl delay of 1 second was used. This however makes crawling ever so slow…This limits the amount of pages to 86400 pages a day which is far from desirable. That would make a very ineffective crawler.
According to https://www.siteground.com/blog/crawl-delay/ Google uses no crawl delay.
Multithreaded crawling
If we have to respect crawl-delays we could build a complex system that keeps track of the last crawl action on each respective host. I, however, found it much easier to just start a new thread for each host and sleep for 1 second between each page request for that host. For each host a shared collection of pages that need visiting was created. Threads can add pages to other hosts. The amount of threads however quickly exceeds the resources that are available.
A thread limiter was introduced and maximizes up to 20 threads to be used.
The drop point to start crawling was en.wikipedia.org.
It turns out crawling wikipedia would result in 30% of errors. It still needs to be examined if this is truly missing pages or something wrong with the tool. Hosts with a .com domain were not crawled as most commercial domains are not all that interesting when it comes to content.
An alternative to robots.txt
I figured that rather than having crawlers going over all pages it would be much more efficient to just generate one big compressed file with all the content for the host. This file would only contain flat text content and on which page to find it, no ads, no formatting, no scripts, … While this would require some work from the site maintainers side it would reduce crawler induced traffic and guarantee that bots don’t mess with the internals of their website. According to a 2013 study over 61% of the web traffic is generated by crawling. For more info follow the above link.

The Learchy crawler code is available here:
https://github.com/denshade/Learchy
