
It was a slow evening. I was watching ‘Elementary’ which is a modern take on ‘Sherlock Holmes’. Holmes smirked as he convincingly had caught the criminal by applying the ever so mysterious Stylometry. By cleverly combining the three sentences the criminal had written he could easily reveal that it was the suspect on the chatroom. Isn’t Sherlock a genius?
After some careful examination I found out that Stylometry actually is a thing and has been since Principes de stylométrie (1890). So I wanted to give it a stab. I wrote a program to identify if I wrote a piece or not, much like Sherlock. Here is my feeble attempt.
Classic method: distance between function words
First I tried to use a somewhat simple classic method as described here:
I sought for a writer invariant. Wikipedia states that: “An example of a writer invariant is frequency of function words used by the writer.”
As example I used my thesis and a long report I have written for work and compared it to the Bible, more specifically: Genesis. Out of this I extracted the relevant ‘function words’ and their frequencies relative to the total amount of words I had used.
Combine these and you have a few nice vectors. I figured by calculating the euclidean distance between these vectors I could see how different one text is compared to another. And voilà the first proof that I didn’t write Genesis was in.
- Bible vs. mails: 814.72
- Bible vs. thesis: 906.4926
- Mails vs. thesis: 288.67
But what is far away? Is 814 sufficiently far away enough to be convincing? Also I hear you think, well that isn’t a modern approach at all! Worry not here comes the neural network solution.
The Neural network solution
The idea is simple. Throw my mails and thesis at a neural network with label 1(I wrote it). Throw some other text at it and label it 0(I didn’t write it).
A neural network however does not take text, however. So we need to create a shared dictionary first. Then replace the coded documents which will be ready to feed to our neural network.

To do this exercise I used tensorflow together with python 3.6. And now for my neural network architecture:
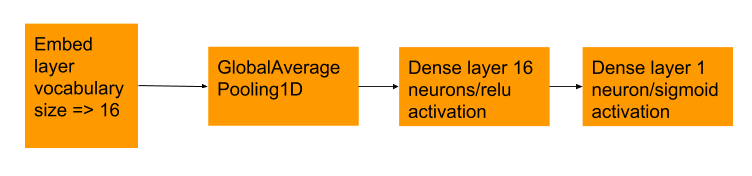
I borrowed this neural network from the standard tensorflow examples which I can now proudly act as if my own. But how does it perform?

Conclusion
With the impressive graph I’ve shown you above you must deem me the next Sherlock, only, even more arrogant. The graph shows a 100% accuracy on all of the data I fed it, compared to a test and validation set of 10% each. The dataset however was pathetically small.
The bad news is if you are a regular person as me and not a known writer you will not have enough training data. The above graph is an excellent example of overfitting. When it comes to stylometry on regular people using a neural network won’t make a strong case as it suffers from a big amount of overfitting.
